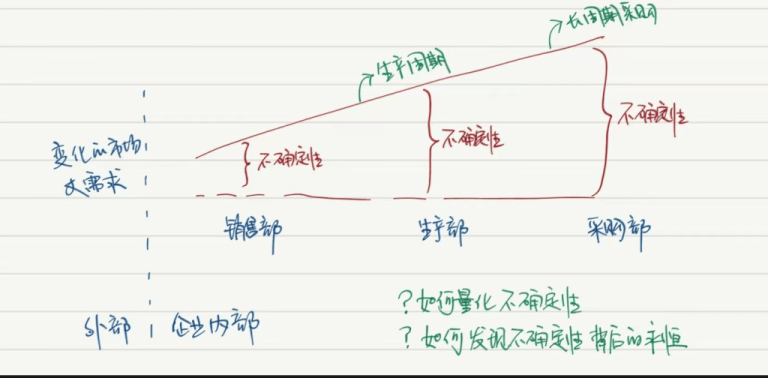
本文摘自《数据可视化分析(第 2 版):分析原理与 Tableau、SQL 实践》by 喜乐君
/
8.1 计算的演进及分类:从Excel、SQL到Tableau
分析世界,计算无处不在。简单如四则运算,Excel的LEFT、SUM函数,SQL中的COUNT语法,复杂关系计算如VLOOKUP、JOIN,高级计算如AVG(SUM)和LOD表达式等组合形式,它们如同“血脉”,以有限的字段组合奠定了无限的分析世界。
熟练驾驭计算需要理解计算的类型及差异,特别是站在业务视角理解这一切。本节先简述计算与业务的关系,之后借助工具进一步介绍。
8.1.1 计算的本质及其与业务过程的关系
计算是“从无到有”的过程,因此计算即抽象。不同计算的抽象化程度有所不同。
比如,从订单日期中计算“年”,对每一行都是确定性的,结果在明细上有意义,在业务过程中有对应,因此抽象化程度较低。而从多行中聚合计算获得“销售额总和”(Excel中称为“求和项”),甚至两个总和进一步获得“利润率”(利润总和/销售额总和),这些聚合在明细表上无意义,在业务过程中无对应,而且随着问题变化结果自动变化,因此聚合计算的抽象化水平更高。
本书中“分析是对业务和数据表的抽象、升华”,指的是包含聚合的高级抽象。
高级分析师务必要从技术、业务多重角度理解计算的分类及其关系。既要理解对应的计算逻辑、功能语法,更要理解彼此的关系、组合。如图8-1所示,勾勒了第3篇的计算分类体系及关键要点。
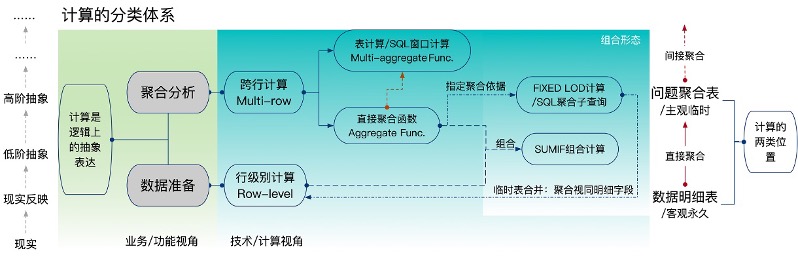
图8-1 计算的分类体系和计算逻辑
从计算的功能和抽象化水平看,计算可以分为两种基本类型。
- 数据准备(Preparation):在数据明细表中,借助计算、数据表关联合并等方式对原始数据进行清理、转换、分组等处理,类型多样,抽象化水平较低,数据在明细上有意义。
- 聚合分析(Analysis):以问题为引导,从数据表明细分组聚合为少数数据,并可进一步比较计算回答问题的过程,聚合可以是一次聚合、多次聚合,从而实现高级抽象。聚合结果仅在指定问题上有意义,问题是对业务的抽象。
如果站在数据明细表的角度,数据准备都是对每一行数据而言的,计算不会跨行[1]。聚合分析是相对问题而言的,计算一定会跨行,因此,笔者常把计算分为“行级别计算”和“跨行计算”。
- 行级别计算(Row Level Calculation):在单一明细行(Record)中实现的计算,如YEAR([订单日期])和[销售额]-[成本额]计算,单行的计算是低级抽象的计算。
- 跨行计算(Multi-row Calculation):跨多个明细行(Record)的计算,如SUM([销售额]),RANK( SUM([销售额]) ),前者是明细表的聚合,后者是聚合表的排序计算。
本章中,除非特别强调,聚合均指以SUM、AVG为代表的直接聚合,基于聚合值的二次聚合、相对指定详细级别的预先聚合,则是后续章节的任务。
充分地理解“计算即抽象”,再从业务和抽象程度角度理解计算的分类,是业务用户进入大数据分析的关键。本书借Tableau和SQL解读分析背后的原理,帮助读者跨工具掌握业务分析。
8.1.2 以Excel理解详细级别与计算的两大分类
以“示例一超市”数据为数据源,用Excel[2]完成如下问题:
“2021年,各类别、各品牌的销售额(总和)、(合计)利润率”
业务过程映射为数据明细表,在数据明细表中完成计算分析。整个思考过程如下。
首先,理解数据明细表及其对应的业务过程。
数据表明细行是业务过程的反映,是分析聚合的起点。在“示例一超市”数据中,“销售明细表”的每一行代表一笔完整的业务交易,描述“谁、在何时、何地、给谁、以何种方式、提供了什么产品(交易过程),以及该交易的度量属性(数字记录)”,数据明细表的唯一性用“订单ID*产品ID”表示。
表8-1展示了数据表的部分关键字段。
表8-1 销售明细表(部分)
| 客户名称 | 订单日期 | 订单ID | 类别 | 产品名称 | 数量 | 销售额 | 利润 |
| 曾惠 | 2021/4/27 | US-2021-1357144 | 办公用品 | Fiskars 剪刀, 蓝色 | 2 | 130 | -61 |
| 许安 | 2021/6/15 | CN-2021-1973789 | 办公用品 | GlobeWeis 搭扣信封, 红色 | 2 | 125 | 43 |
| 许安 | 2021/6/15 | CN-2021-1973789 | 办公用品 | Cardinal 孔加固材料, 回收 | 2 | 32 | 4 |
| 宋良 | 2021/12/9 | US-2021-3017568 | 办公用品 | Kleencut 开信刀, 工业 | 4 | 321 | -27 |
| 万兰 | 2020/5/31 | CN-2020-2975416 | 办公用品 | KitchenAid 搅拌机, 黑色 | 3 | 1376 | 550 |
| 俞明 | 2019/10/27 | CN-2019-4497736 | 技术 | 柯尼卡 打印机, 红色 | 9 | 11130 | 3784 |
其次,确认分析需求,分解每个问题的构成。
业务需求分解为问题,每个问题必然包含3个部分(筛选范围、问题描述和问题答案)。数据合并或计算弥补数据明细表或问题中的字段不足。解析如下。
筛选范围:“2021年”代表问题的分析范围,对应【订单日期】字段,它是“订单日期在2021年”的简化形式。
- 问题描述:维度描述问题,这里的“类别、品牌”构成问题详细级别,问题详细级别是答案聚合的分组依据。缺少的“品牌”字段需要借助计算弥补。
- 问题答案:聚合是分析的本质。聚合的数据值从明细中计算而来,对应一个虚拟的聚合表。“销售额总和”对应SUM求和聚合函数,合计利润率则是两个聚合值的直接比较。
再次,使用计算弥补数据明细表中字段的不足,而后完成汇总分析。
- 筛选范围:数据明细表中【订单日期】对应类似“2021/6/15”的精确日期,并没有年度字段“2021”。日期要先转换为年,而后完成筛选,这个过程就是“提取日期部分函数”和逻辑判断的计算过程,即YEAR([订单日期])= 2021。
- 问题描述:问题中缺失的“品牌”可以从字段【产品名称】中拆分计算,也可以由其他数据表合并而来(比如从“产品信息表”中匹配获得品牌信息),计算的方法优先于数据合并。这里使用SPLIT函数或LEFT函数完成。
- 问题答案:问题中的“销售额(总和)”来自数据明细表中的【销售额】字段直接聚合。“利润率”则需要利润总和、销售额总和的聚合比值,是聚合函数和算术计算的组合,可以理解为包含聚合函数的表达式(SUM([利润])/SUM([销售额]))。
在这个过程中,每个部分都需要借助计算,计算肩负两大功能:数据准备(弥补数据表字段不足)、聚合分析(抽象概括,弥补问题中字段不足)。
“品牌”由【产品名称】字段拆分而来,可以使用LEFT函数取第一个空格左侧的部分(暂不考虑其他特殊情况)。如图8-2所示,在明细行后面增加辅助列字段“品牌”,完成计算。
= LEFT(N2,FIND(” “,N2))
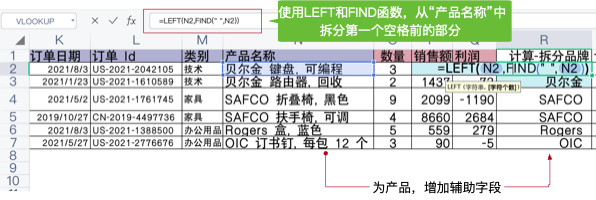
图8-2 在Excel数据明细中增加计算,补充“品牌”
由于每个产品名称必然对应一个品牌,计算是在每一行上执行的,绝对不会跨行(即N3单元格的产品名称,必然对应R3单元格的品牌),这种计算被称为“行级别计算”(Row Level Calculation)。
相比之下,“销售额(总和)”和“利润率”是完全不同的计算逻辑,因此要在数据透视表中完成。
如图8-3所示,在WPS Excel中插入“数据透视表”,默认打开新工作表,将【销售额】和【利润】度量字段拖入“值”,将【类别】和【品牌】拖入“行”,就会生成如下的聚合。以“技术”类别中黑的“贝尔金”为例,它的销售额(2632)是由两个值相加而来的(1195+1437),是典型的纵向跨行计算,而非水平的单行计算。其他聚合同理(这里样本小,有的部分只有一个值)。
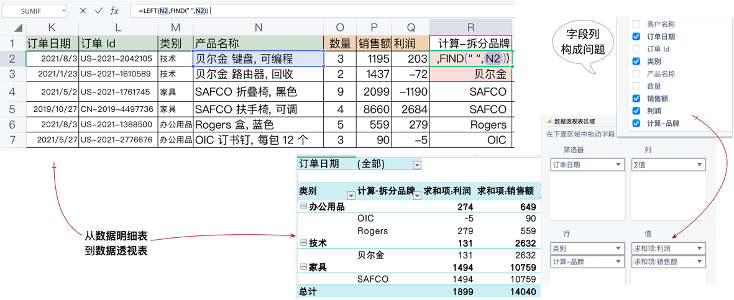
图8-3 Excel数据透视表实现两个度量的聚合
计算的关键是如何计算“利润率”。
准确地说,这里的“利润率”是“各类别、各品牌的利润率”,是各类别、各品牌的利润总和与销售额总和的比值,而非“每一行的利润率”。聚合在“透视表”完成。
如图8-4所示,在菜单栏中选择“分析→字段、项目→计算字段”命令(见图8-4位置①),弹出“插入计算字段”窗口,在“公式”中选择字段并插入,完成计算公式“=利润/销售额”(见图8-4位置②),计算字段【透视表-利润率】会添加到数据透视表中,增加了第三个度量列(见图8-4位置③)。
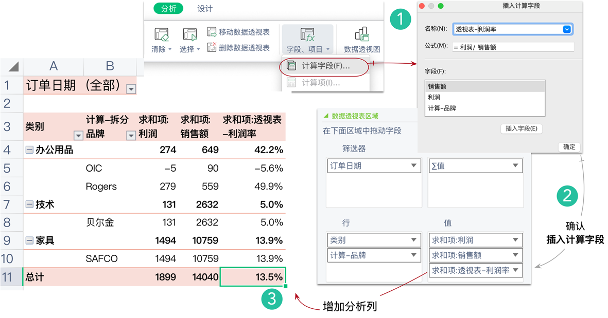
图8-4 在Excel数据透视表中增加聚合的计算字段
注意,利润率计算看似没有“求和项”或SUM等聚合方式,其实是默认聚合的,后面详解。
Excel数据透视表中自动增加“小计”和“总计”,13.5%的总计利润率,是1899/14040的求和项比值。熟悉Excel的读者也可以调整透视表中的行列字段,实现不同层次的求和项计算,如图8-5所示,在不同详细级别的透视表中,总计利润率都是相同的(13.5%)。数据透视表实现了同一份数据、不同视角的层次分析,不管是最高详细级别分析(见图8-5位置①),还是每个类别(见图8-5位置②)。
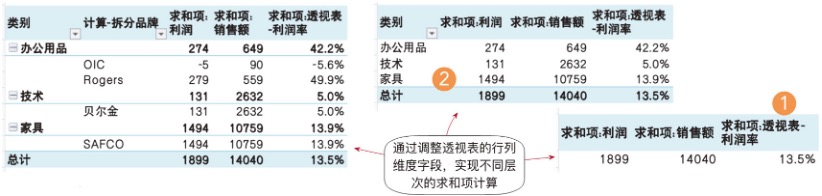
图8-5 在Excel中对不同层次问题的“透视分析”
这里重点说一下“透视”。中文的“透视”本是一种绘画手法,“在平面上表现物体的空间位置距离和轮廓投影”,也被称为“远近法”,与业务探索、钻取分析(roll up、drill down)的精神相契合,也许这就是中文翻译“透视”的来源。业务分析需要在众多的维度字段中切换分析视角,分析层次有高低,如同视角有远近;问题之间的钻取变化,如同相机拍摄中镜头之远近。
不过,“数据透视表”的英文是Pivot Table,Pivot的本意是“支点、中心”(名词)、“使旋转”(动词),后来延伸出了“核心任务”“改进以符合特定需求”等抽象含义[3]。具体到数据领域,Pivot的本意是“转置”,在数据存储还在软盘阶段的年代,Pivot Table用于交换明细表中的列字段位置。随着数据量的增加,透视表的功能从“明细行转置”升级为“先按需聚合再转置”。大数据时代,透视表功能受限,它无法完成多表合并,特别是先聚合再合并等高级场景,于是微软开发了Power Pivot,泛指数据建模技术,用于创建数据模型、建立关系,以及创建计算,中文翻译为“超级透视表”。
从转置、按需聚合,到多数据模型处理,Pivot的范围越来越广泛,英文Pivot的含义足以概括这一切,中文的“透视表”和“超级透视”都很难代表如此广泛的功能。“表哥”“表姐”要当心莫被“透视”的翻译影响了对聚合的理解。
说这么多,旨在帮助大家理解透视背后的本质——聚合,并理解聚合的过程。
Excel透视是从数据明细表到数据透视表的由多变少的过程,透视即聚合,聚合回答问题。
Excel是很多分析师进入数据分析世界的第一站,借助Excel的明细表和透视表,分析师可以构建如图8-6所示的计算分类。数据明细表用于记录业务运营过程,而对数据透视表的分析则用于辅助业务决策。熟悉它们的分类和逻辑对应关系,是进一步理解SQL和Tableau逻辑的基础。
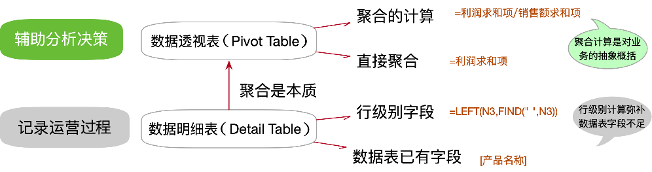
图8-6 清晰区分Excel的两个数据位置、两类计算
接下来,从Excel的局限性出发理解SQL,再从SQL的局限性去理解Tableau。
8.1.3 从Excel“存取一体”到“数据库-SQL”的存取分离
随着数据量的剧增,Excel分析能力遇到瓶颈,新的工具开始兴起,最典型的是SQL(结构化查询语言)。分析师若能掌握SQL语言用以数据库查询和分析,可以极大地提高数据分析的效率。
举个例子,说明从本地数据到“数据库/SQL结构”(Database/SQL)的必要性。
20世纪70年代~20世纪80年代,父辈工资普遍百元左右,每月现金发放,钱少人多,他们换成零钱放在抽屉(“钱包”)里一点点花,“存取简单、随取随用”。随着经济快速发展,如今一线城市“打工人”年薪都要几十万元起步动辄百万元计,这么多钱显然不能放在家里,存不方便、取不安全,于是把钱存入银行(“钱库”),银行提供了标准、统一、高效、安全的存取款服务;需要大额现金就要到银行柜台填写标准的“取款单”,柜员代为从“钱库”提取。对于大额资金,存款、取款分离是提高安全性、便捷性的重要方法。如图8-7左侧所示。
数据的写入、查询也是类似的过程,数据量少时直接用纸笔或Excel(存取合一);随着数据量剧增,数据存储要和数据查询严格分开,于是数据库(Database)兴起,代表有MySQL、Oracle等。数据库都提供了标准化的查询工具,如同银行的柜台或者ATM界面,可以满足标准化、安全性、大数据查询的要求。有兴趣的读者可以在网上查询“SQL的起源”,了解数据库与SQL的历史。
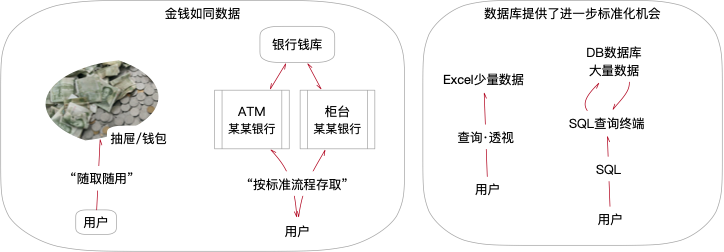
图8-7 从Excel到SQL,如同从钱包到银行
数据存储与查询相分离,是数据发展史具有里程碑意义的大事件。
当然,变化的是工具,不变的是方法和逻辑。SQL如今也有国际性标准可遵循。
以MySQL为例,可以使用如下的SQL语句完成8.1.2节中的问题“2021年,各类别(Category)、各品牌(Brand)的销售额(总和)(Sales)、(合计)利润率(Profit Margins)”。
SELECT category,
SUBSTRING_INDEX(`Product Name`,' ',1) AS Brand, -- 从Product Name中拆分空格前面的部分
SUM(Sales) AS Sales,
SUM(Profit)/sum(Sales) AS 'Profit Margins' -- 合计利润率与销售额总和的比值
FROM tableau.superstore_en -- 查询的明细表
WHERE YEAR(`Order Date`)=2021 -- 筛选范围
GROUP BY Category, Brand; -- 维度是聚合依据,GROUP BY对应维度、问题详细级别如图8-8所示,使用SQL的SUBSTRING_INDEX函数获取“Brand”(品牌),用两个SUM函数和算术相除,计算“Profit Margins”(利润率)。
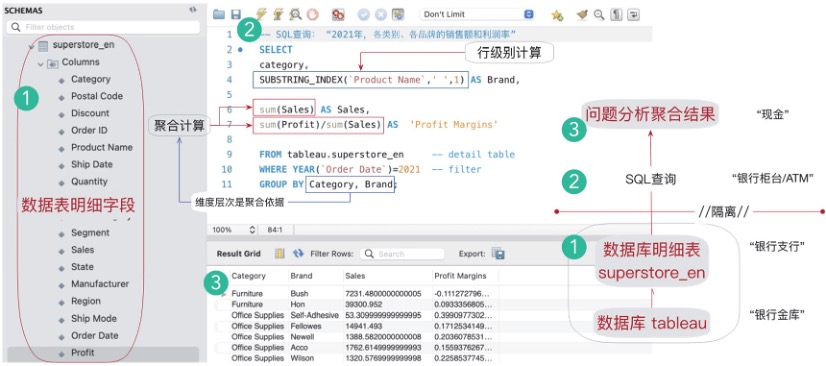
图8-8 SQL结构化数据库交互语言与分析过程
在大数据时代,分析师要从过去的“眼见明细为真实”向抽象分析转变。
钱少的时候,每个人都关注每一分钱如何节省、如何花;钱多的时候,金钱只是银行卡的数字,花钱更变成了在线支付,无人关心自己的钱被银行存放在哪里(如果要细究,你也找不到位置)。
同理,SQL查询也不关注数据库明细表,只关注聚合结果及其组合变化。从小数据到大数据时代,分析的本质没有变化。分析是从数据库明细表到特定问题交叉表的聚合过程。
在分析过程中,不管是明细中缺少的字段(比如品牌),还是问题中缺少的字段(比如利润率),都可以借助计算弥补。行级别计算完成数据准备,聚合计算完成业务分析。
在数据库已经普遍存在的当下,一旦掌握了SQL,很容易迷恋于它的优雅、快捷与强大,再也不想“导出数据→打开Excel→创建透视表”了。
当然,SQL也有它的不足,这就催生了Tableau等大数据可视化分析工具。
Excel还能转化为图形甚至放到PPT中,SQL则是交叉表(Cross Table)的世界。SQL作为数据库标准化存取数据工具及“数据库交互语言”,它完全围绕数据(Data)而生,无法转化为图形(Chart),更非可视化分析(Visualization)。
但是在大数据环境中,注意力成为稀缺资源,可视化是帮助领导快速获得信息、辅助业务决策的重要呈现方式。有没有一种工具,既能继承和使用SQL的标准化数据语言,轻松与大数据交互查询,又能像Excel一样随时转化为图形,甚至融入业务经验构成分析仪表板,图文并茂地呈现“数据故事”呢?
这就是本书的主角:Tableau。
Tableau继承了SQL的优势,可以连接广泛的数据库,与各种主流数据库轻松交互,内置多种数据处理、聚合分析函数,降低了学习成本(不用学习一门新的编程语言),并且,默认生成可视化图形。它将数据查询、计算、可视化多个要素融为一体,简单快捷、灵活易用,为广大的业务用户提供了进入大数据分析世界的捷径。
因此,笔者选择了Tableau,并借助Tableau介绍Tableau之外的分析原理。
8.1.4 集大成者Tableau:将查询、计算和展现融为一体
Tableau Desktop可以直接连接Excel、CSV、MySQL等本地数据或者数据库。这里,使用“示例一超市”数据分析问题“2021年,各类别、各品牌的销售额(总和)、(合计)利润率”。
Tableau Desktop有两个主要操作界面,“数据源”界面和“可视化”界面。其中“数据源”界面如同Excel明细表,是聚合的起点,如图8-9所示。
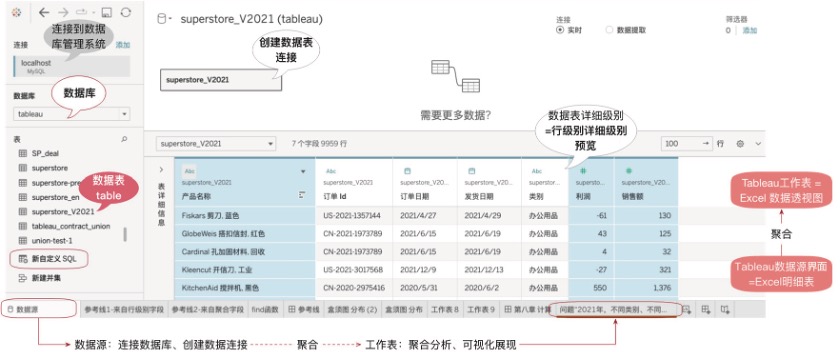
图8-9 Tableau数据源界面,如同Excel明细,明细是聚合的起点
点击创建工作表,如同Excel“数据透视表”的聚合分析就开始了,设计理念和Excel数据透视表多有类似,又截然不同。
Tableau的关键在“标记”,它为可视化赋予了图层重叠的理念。
第一步,使用已有业务字段构建基本可视化。
如图8-10所示,在Tableau工作表中,从左侧表字段中依次双击【销售额】和【类别】字段(注意先双击度量字段),并拖动【订单日期】字段到筛选器,选择“年→2021”,就会生成“2021年,各类别的销售额总和”条形图,维度、度量、筛选器分别对应图8-10所示位置①、位置②和位置③,这奠定了接下来视图的基本框架。
这里的关键是图8-10位置④和图8-10位置⑤,品牌需要从【产品名称】字段拆分而来,利润总和需要计算进一步升级为“利润率”。
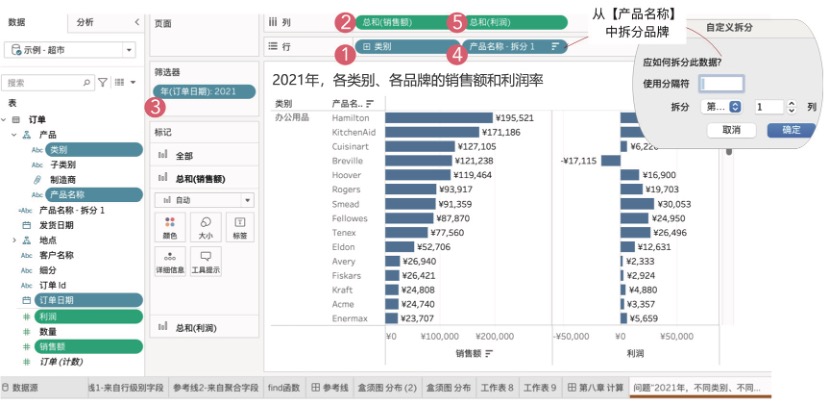
图8-10 构建主视图,并完成行级别的品牌计算
第二步,行级别计算,用SPLIT函数获取“品牌”,弥补数据表业务字段的不足。
在【产品名称】字段上右击,在弹出的快捷菜单中选择“变换→自定义拆分”命令,在弹出的窗口中输入分隔符(输入一个空格),选择第1列。如图8-10右上角所示。
拆分是常见的数据处理方式,不同工具在实现方式上有所差异,如下所示。
- Excel使用LEFT和FIND函数结合:= LEFT(N2,FIND(” “,N2))
- SQL使用字符串提取函数:SUBSTRING_INDEX(`产品名称`,’ ‘,1)
- Tableau使用“变换→拆分”功能,对应拆分函数:SPLIT([产品名称], ‘ ‘,1)
在本书中,笔者把在明细行中完成的计算称为“行级别计算”(Row Level Calculation),它们的定位是数据准备,用于补充数据表字段的不足。后续还会专门介绍。
第三步,在视图层次完成聚合计算,获得“利润率”分析结果。
如何完成聚合,进而计算聚合的比值(利润率),是重点。
在8.1.2节中,在Excel数据透视表中创建计算字段,输入“利润/销售额”计算利润率;在SQL中,则使用SUM(Profit)/SUM(Sales)完成“利润率”计算,Tableau也是同理。
“各品牌的利润率”需要两个聚合字段相除得到,即SUM([利润])/SUM([销售额])。Tableau创新性的“即席计算”功能简化了操作,只需要在列位置空白处双击即可创建计算胶囊,或者双击总和(利润)胶囊,把前面的总和(销售额)拖曳进来创建两个聚合字段比值,如图8-11所示。
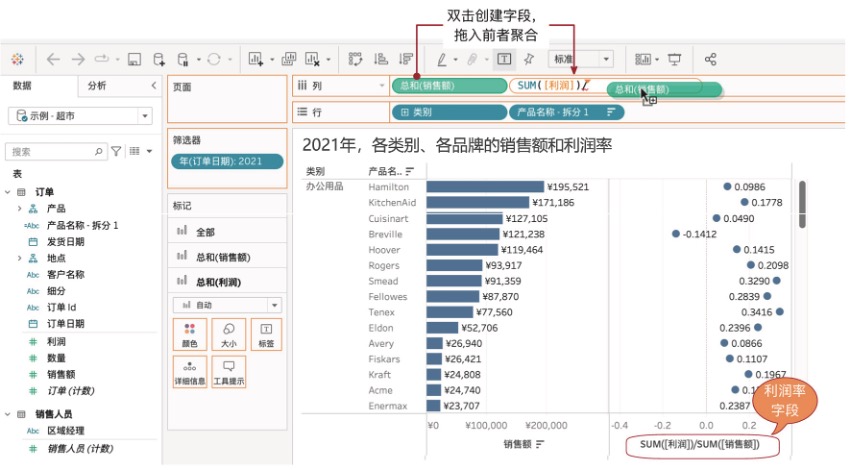
图8-11 快速创建计算,完成聚合的利润率
很多人受Excel数据透视表的影响,错误使用[利润]/[销售额]计算“利润率”。Excel数据透视表的不规范语法是“表哥”“表姐”通往业务分析的障碍。
Excel数据透视表的[利润]/[销售额],本质是聚合后的[求和项;利润]/[求和项;销售额]比值计算,而非字面上的明细字段比值。行级别的利润和销售额之比是缺乏业务意义的,利润率只有在大样本上做聚合比值,才能反映业务的规律性——每销售100元产品所带来的边际利润。
不管是什么行业,利润率都是聚合后的比值,而绝非明细表行级别的比值计算,此类抽象指标的关键是包含聚合——笔者将其称为聚合指标的二次抽象。
聚合计算是典型的分析,分析是对业务的升华和抽象。它的目的和行级别计算的数据准备截然不同。
第四步,根据需要调整视图详细级别并增加对比。
为进一步体现Tableau的灵活性和易用性,这里增加参考线对比。
“没有对比就没有分析”,常见的比较有同期比较(同环比)、目标进度比较、标杆值比较等,还有相对更高级别的均值比较。比如,哪些品牌的利润率低于所属类别的合计利润率?最常见、快捷的方法,是使用参考线增加更高详细级别的聚合。
如图8-12所示,从“分析”窗格中拖曳“参考线”到视图中,选择“区”,在弹出的窗口中,选择“合计”为参考线值计算方式。修改一下标签显示方式,此时,每个类别的合计利润率标记出来了。比如技术对应的参考线为13.2%。
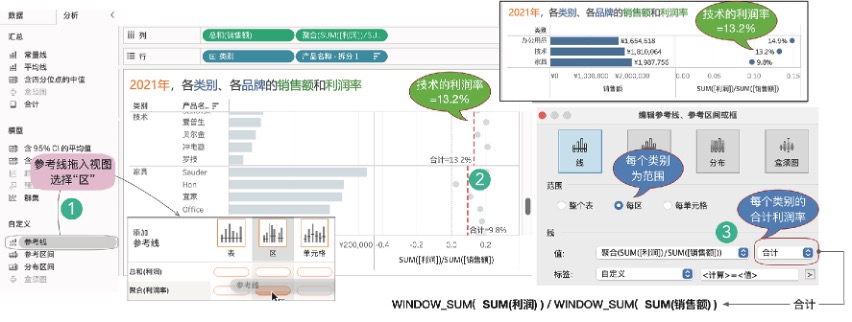
图8-12 使用参考线增加更高层次的聚合比值利润率
相比视图的详细级别(各类别、各品牌的利润率),“合计利润率”本质上是更高聚合度详细级别的计算(各类别的利润率)。拖曳即可完成多个详细级别分析,从而对比不同级别的指标,是Tableau相比Excel和SQL的巨大进步。参考线之所以被称为“分析”窗格,是因为它们都是对已有聚合值的进一步计算,是典型的抽象的二次抽象。因此,参考线是通往高级分析的桥梁,它让业务用户也可以轻松完成之前专业人员才能完成的高级分析。参考线背后是表计算,相关内容在第9章介绍。
接下来,笔者进一步总结Excel、SQL、Tableau中品牌字段、利润率计算背后的原理。
[1] 这里的数据准备,指狭义的字符串拆分、查找等计算,不涉及先聚合再合并的复杂情形。
[2] 本书Excel使用金山公司的WPS Excel,逻辑与Microsoft Excel基本一致。
[3] 《欧路字典》在线版 Pivot n.(1)axis consisting of a short shaft that supports something that turns ,支点、枢纽(2)the person in a rank around whom the others wheel and maneuver ,核心,最重要的人;v. turn on a pivot(使)在枢轴上旋转;(以脚为支点)转身;(为机械装置)提供枢轴。